
 M.S. in the College of Artificial Intelligence
M.S. in the College of Artificial IntelligenceI am a second-year Master student in the College of Artificial Intelligence at China University of Petroleum, Beijing, where I conduct research in the intersection of Computer Vision and Generative Models under the supervision of Prof. Yaru Xue. Prior to that, I received my B.S. in Telecommunication Engineering from Zhengzhou University.
My research interests lie broadly in developing generative model, and use them to solve computer vision problems, with a current focus on medical inverse problem solving.
Outside of my academic work, I am a passionate self-learner with a strong curiosity for various areas across computer science.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
China University of Petroleum, BeijngThe College of Artificial Intelligence
M.S. in Information and Communication EngineeringSep. 2023 - June. 2026 (expected) -
 Zhengzhou UniversityB.S. in Telecommunication EngineeringSep. 2019 - June. 2023
Zhengzhou UniversityB.S. in Telecommunication EngineeringSep. 2019 - June. 2023
Experience
-
 Software Engineering Center Chinese Academy of SciencesResearch InternJuly 2024 - Aug 2024
Software Engineering Center Chinese Academy of SciencesResearch InternJuly 2024 - Aug 2024 -
 Sinopec Engineering Co., Ltd., GuangzhouInternJuly 2023 - Aug 2023
Sinopec Engineering Co., Ltd., GuangzhouInternJuly 2023 - Aug 2023 -
 China Potevio Information Technology Co., Ltd.InternJan 2022 - Feb 2022
China Potevio Information Technology Co., Ltd.InternJan 2022 - Feb 2022
Honors & Awards
-
Third Prize Scholarship of China University of Petroleum, Beijing2025
-
Third Prize Scholarship of China University of Petroleum, Beijing2024
-
Merit Intern of Potevio Information Technology Co., Ltd.2022
-
Third Prize Scholarship of Zhengzhou University2022
-
Second Prize Scholarship of Zhengzhou University2021
Selected Publications (view all )
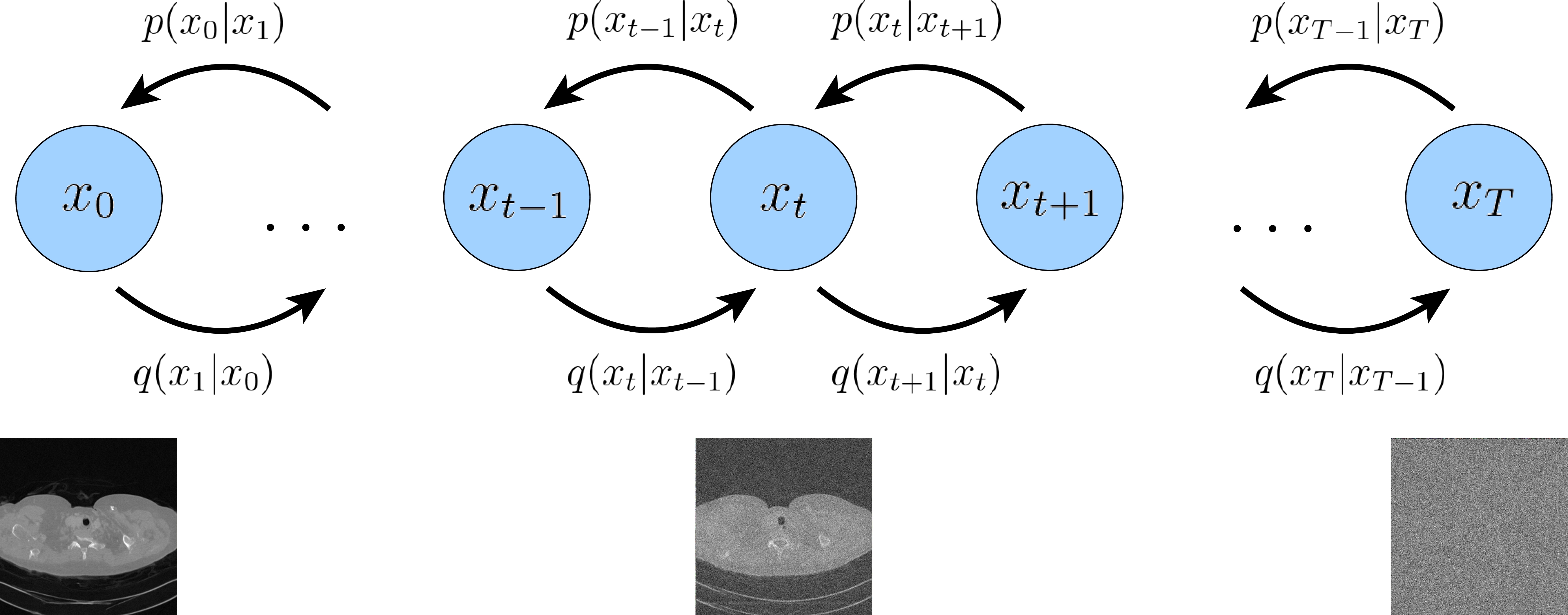
PC-POCS sampler to reconstruct a low-dose computer tomography image consistent with both the prior and the measurements
Yuchen Quan#, Yaru Xue (# corresponding author)
Submitted to The IEEE International Conference on Bioinformatics and Biomedicine(BIBM) 2025
Reconstructing medical images from partial measuremets is a critical inverse problem in Computer Tomography, essential for reducing radiation exposure while maintaining diagnostic accuracy, addressing challenges of small size and poor resolution in CT data. Existing solutions based on machine learning typically train a model to directly map measurements to medical images, relying on a training dataset of paired images and measurements synthesized using a fixed physical model of the measurement process; however, this approach greatly hinders generalization to unknown measurement processes. To address this issue, we propose a fully unsupervised technique for solving the inverse problem, leveraging score-based generative models to eliminate the need for paired data. Specifically, we first train a score-based generative model on clean conventional-dose medical images to capture their prior distribution. Then, given measurements and a physical model of the measurement process, we introduce a sampling method to reconstruct an image consistent with both the prior and the measurements. Empirically, we observe comparable or better performance to other sampling techniques in several medical imaging tasks in Computer Tomography, while demonstrating considerably better generalization to unknown measurement processes.
PC-POCS sampler to reconstruct a low-dose computer tomography image consistent with both the prior and the measurements
Yuchen Quan#, Yaru Xue (# corresponding author)
Submitted to The IEEE International Conference on Bioinformatics and Biomedicine(BIBM) 2025
Reconstructing medical images from partial measuremets is a critical inverse problem in Computer Tomography, essential for reducing radiation exposure while maintaining diagnostic accuracy, addressing challenges of small size and poor resolution in CT data. Existing solutions based on machine learning typically train a model to directly map measurements to medical images, relying on a training dataset of paired images and measurements synthesized using a fixed physical model of the measurement process; however, this approach greatly hinders generalization to unknown measurement processes. To address this issue, we propose a fully unsupervised technique for solving the inverse problem, leveraging score-based generative models to eliminate the need for paired data. Specifically, we first train a score-based generative model on clean conventional-dose medical images to capture their prior distribution. Then, given measurements and a physical model of the measurement process, we introduce a sampling method to reconstruct an image consistent with both the prior and the measurements. Empirically, we observe comparable or better performance to other sampling techniques in several medical imaging tasks in Computer Tomography, while demonstrating considerably better generalization to unknown measurement processes.
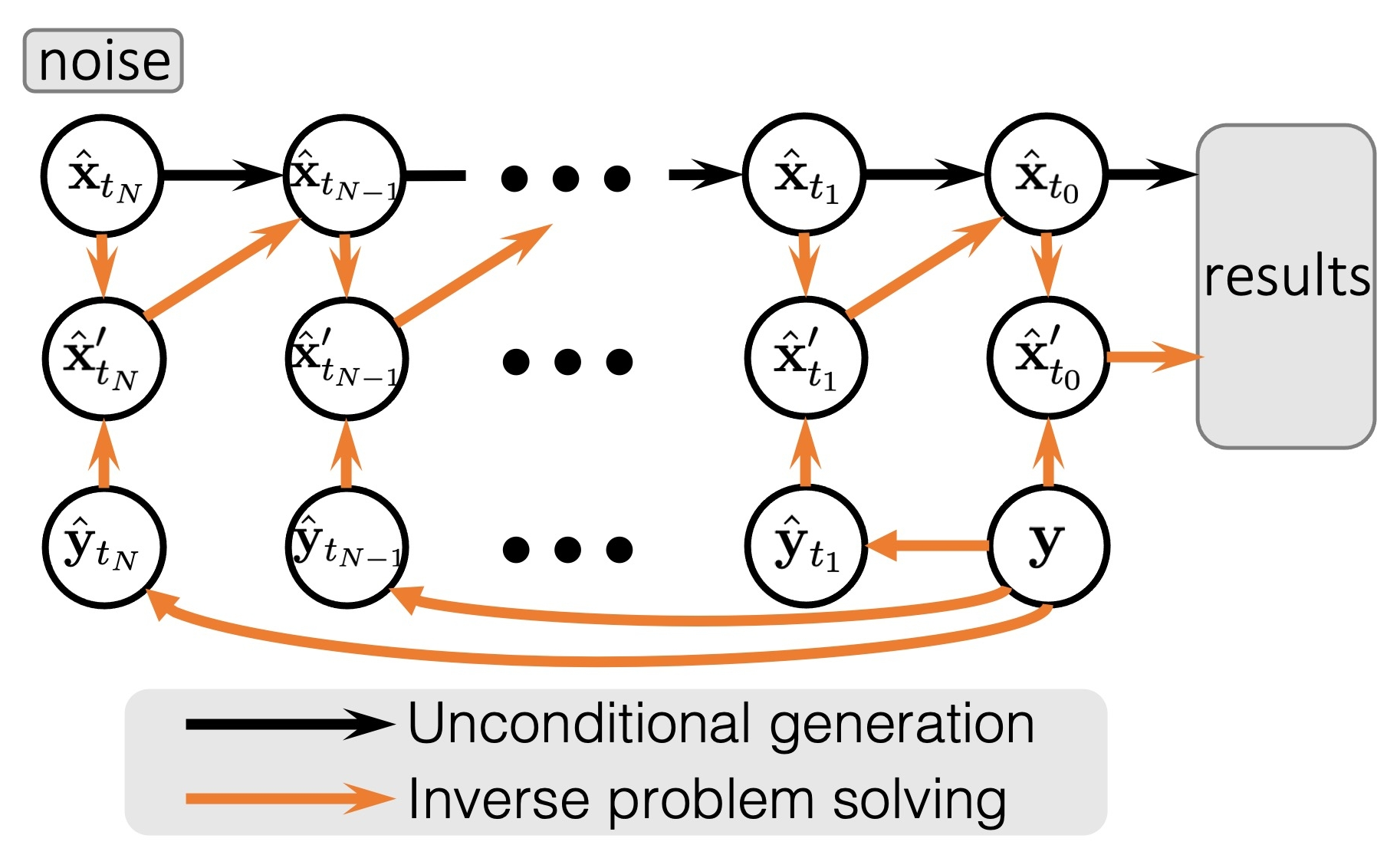
Solving Low-dose Computer Tomography inverse problem by learning the first-order score of the sparse sinogram samples' distribution
Yuchen Quan#, Yaru Xue (# corresponding author)
Submitted to The Pacific Rim International Conference on Artificial Intelligence(PRICAI) 2025
Computer Tomography is widely used to acquire the internal structures of the target object in a non-invasive way. In order to obtain a high-quality reconstruction, densely distributed detectors are always used to improve the sampling rate, which is used to avoid the artifacts caused by angular undersampling. However, the high density of X-Rays is harmful to the human body, which implies to us that sparse-view measurement is urgently needed. Lots of current methods couldn't make full use of the information from different domains, which leads to the failure of getting a reliable reconstruction result. This paper shows that the Low-dose Computer Tomography inverse problem could be solved from the perspective of an inpainting task in the measurement domain(Radon domain). Besides this, a method based on a score-based diffusion model is proposed, and some properties of the sinogram are used to achieve a more reliable result: $14%$ improvement in the metric PSNR and some improvement in the metric SSIM.
Solving Low-dose Computer Tomography inverse problem by learning the first-order score of the sparse sinogram samples' distribution
Yuchen Quan#, Yaru Xue (# corresponding author)
Submitted to The Pacific Rim International Conference on Artificial Intelligence(PRICAI) 2025
Computer Tomography is widely used to acquire the internal structures of the target object in a non-invasive way. In order to obtain a high-quality reconstruction, densely distributed detectors are always used to improve the sampling rate, which is used to avoid the artifacts caused by angular undersampling. However, the high density of X-Rays is harmful to the human body, which implies to us that sparse-view measurement is urgently needed. Lots of current methods couldn't make full use of the information from different domains, which leads to the failure of getting a reliable reconstruction result. This paper shows that the Low-dose Computer Tomography inverse problem could be solved from the perspective of an inpainting task in the measurement domain(Radon domain). Besides this, a method based on a score-based diffusion model is proposed, and some properties of the sinogram are used to achieve a more reliable result: $14%$ improvement in the metric PSNR and some improvement in the metric SSIM.
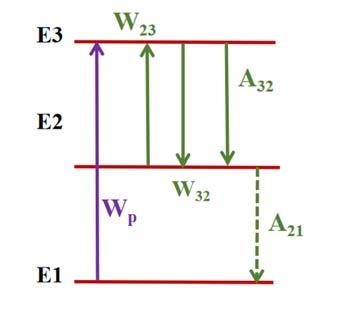
Modeling and numerical simulation optimization of gain spectrum of thulium-doped broadband amplifier based on cat swarm algorithm
Yuchen Quan*, Zhuoer Liu*, Rui Guo* (* equal contribution)
The 5th International Conference on Computing and Data Science 2023
With the development of light technology, especially the maturation of WDM/DWDM technology, the demand for optical amlification of the S-band and S+ band(1450nm~1520nm) is increasing day by day, and the energy level structure of $Tm^{3+}$ has energy level transitions to meet the requirements of S-band and S+ band amplification. Although thulium ion has a very complex energy level structure, TDFA is one of the most promising optical fiber amplifiers for S and S+ bands. At the same time, with the continuous development of computer technology and mathematical theory, the optimization algorithm has been rapidly developed and widely used in recent decades, based on genetic algorithm, simulated annealing algorithm, and other traditional optimization algorithms that have been proved to get good convergence speed and optimization results. In this paper, the thulium-doped fiber amplifier's gain is optimized by using a cat swarm intelligent optimization algorithm to obtain the maximum fiber length and doping concentration.
Modeling and numerical simulation optimization of gain spectrum of thulium-doped broadband amplifier based on cat swarm algorithm
Yuchen Quan*, Zhuoer Liu*, Rui Guo* (* equal contribution)
The 5th International Conference on Computing and Data Science 2023
With the development of light technology, especially the maturation of WDM/DWDM technology, the demand for optical amlification of the S-band and S+ band(1450nm~1520nm) is increasing day by day, and the energy level structure of $Tm^{3+}$ has energy level transitions to meet the requirements of S-band and S+ band amplification. Although thulium ion has a very complex energy level structure, TDFA is one of the most promising optical fiber amplifiers for S and S+ bands. At the same time, with the continuous development of computer technology and mathematical theory, the optimization algorithm has been rapidly developed and widely used in recent decades, based on genetic algorithm, simulated annealing algorithm, and other traditional optimization algorithms that have been proved to get good convergence speed and optimization results. In this paper, the thulium-doped fiber amplifier's gain is optimized by using a cat swarm intelligent optimization algorithm to obtain the maximum fiber length and doping concentration.
Design of mobile station positioning algorithm based on LTE measurement report
Yuchen Quan, Ning Wang
Bachelor Graduation Paper 2023
The improvement of terminal positioning accuracy is an important link in achieving an accurate and efficient assessment of the network coverage degree in a specific area. Compared with traditional Measurement methods, big data analysis based on Measurement Report (MR) is a more accurate and efficient way. MR Data analysis plays an irreplaceable role in the planning, construction, optimization and cost control of LTE(Long Term Evolution) wireless networks. Besides, with the continuous update and development of technology, the demand for positioning services is becoming increasingly urgent. It is urgent to carry out high-precision user location information prediction based on MR Data. MR Data contains the signal environment information of the main service cell and adjacent cells, so it can be used as the basic data for wireless network analysis and optimization. However, the lack of user location information is the main obstacle to the utilization of these data. To this end, this study first introduces the traditional positioning algorithm and, in response to the problem of insufficient positioning accuracy, discusses the AdaBoost+kNN weighted average algorithm, demonstrating its superiority from multiple perspectives.
Design of mobile station positioning algorithm based on LTE measurement report
Yuchen Quan, Ning Wang
Bachelor Graduation Paper 2023
The improvement of terminal positioning accuracy is an important link in achieving an accurate and efficient assessment of the network coverage degree in a specific area. Compared with traditional Measurement methods, big data analysis based on Measurement Report (MR) is a more accurate and efficient way. MR Data analysis plays an irreplaceable role in the planning, construction, optimization and cost control of LTE(Long Term Evolution) wireless networks. Besides, with the continuous update and development of technology, the demand for positioning services is becoming increasingly urgent. It is urgent to carry out high-precision user location information prediction based on MR Data. MR Data contains the signal environment information of the main service cell and adjacent cells, so it can be used as the basic data for wireless network analysis and optimization. However, the lack of user location information is the main obstacle to the utilization of these data. To this end, this study first introduces the traditional positioning algorithm and, in response to the problem of insufficient positioning accuracy, discusses the AdaBoost+kNN weighted average algorithm, demonstrating its superiority from multiple perspectives.